简介
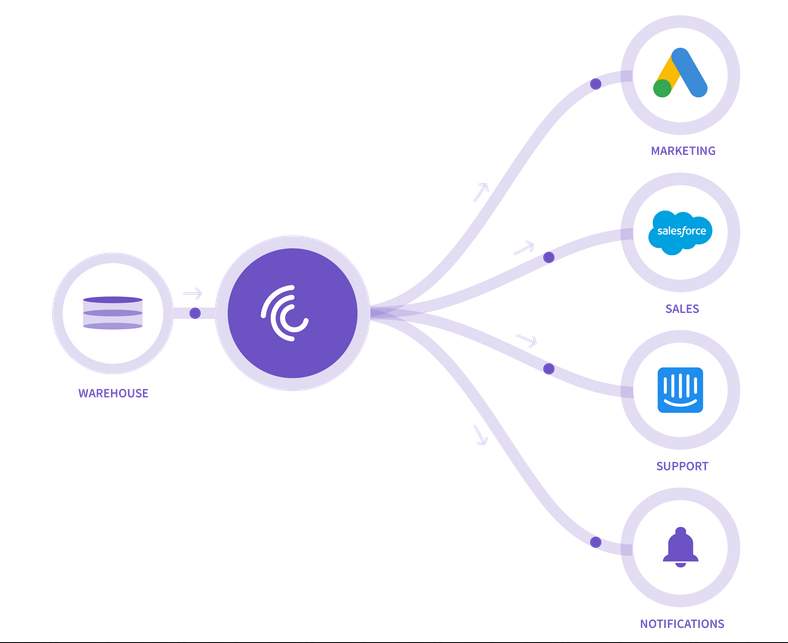
反向ETL
- 核心在于 DataWareHouse 数据分发到下游系统
- 相较于etl 往往实现的是 业务数据收集的功能,而反向etl工具实现的是数据分发的功能.
- 同类的还有
Census``Grouparoo - 反向etl值得学习的地方在于
sink的灵活 集成
增量功能
castled 实现了 增量/全量的推送功能,基于 snapshot实现增量功能
其源码 /connectors模块下的 io.castled.warehouses.connectors.postgres包中大概提示了其在使 pg source 时的 diff 的核心逻辑:
通过 pg的except配合 uncommit_snapshot和 commit_snapshot实现了数据diff,进行增量推送.
安装试用
docker-compose: 下载源码,其中 .env和docker-compose.yaml 放到 /opt/castled中执行
docker-compose up -d
源码学习
DataPoll
对于不同的 source 而言,diff 功能的实现并不相同,但逻辑时相通的. 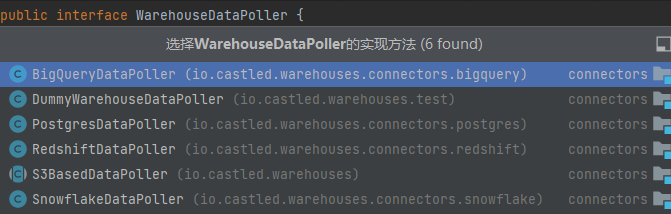
java
package io.castled.warehouses;
import io.castled.constants.ConnectorExecutionConstants;
import io.castled.warehouses.models.WarehousePollContext;
import io.castled.warehouses.models.WarehousePollResult;
import java.nio.file.Path;
public interface WarehouseDataPoller {
WarehousePollResult pollRecords(WarehousePollContext warehousePollContext);
WarehousePollResult resumePoll(WarehousePollContext warehousePollContext);
void cleanupPipelineRunResources(WarehousePollContext warehousePollContext);
void cleanupPipelineResources(String pipelineUUID, WarehouseConfig warehouseConfig);
default Path getPipelineRunUnloadDirectory(String pipelineUUID, Long pipelineRunId) {
return ConnectorExecutionConstants.WAREHOUSE_UNLOAD_DIR_PATH.resolve(pipelineUUID).resolve(String.valueOf(pipelineRunId));
}
default Path getPipelineUnloadDirectory(String pipelineUUID) {
return ConnectorExecutionConstants.WAREHOUSE_UNLOAD_DIR_PATH.resolve(pipelineUUID);
}
}其中核心在于 pollRecords和 resumePoll, 后者区别是非首次推送
java
private String getDataFetchQuery(WarehousePollContext warehousePollRequest, List<String> bookKeepingTables) {
String committedSnapshot = ConnectorExecutionConstants.getQualifiedCommittedSnapshot(warehousePollRequest.getPipelineUUID());
String uncommittedSnapshot = ConnectorExecutionConstants.getQualifiedUncommittedSnapshot(warehousePollRequest.getPipelineUUID());
if (bookKeepingTables.contains(ConnectorExecutionConstants.getCommittedSnapshot(warehousePollRequest.getPipelineUUID()))) {
return String.format("select * from %s except select * from %s", uncommittedSnapshot, committedSnapshot);
}
return String.format("select * from %s", uncommittedSnapshot);
}pg的实现核心便是上面的代码.
App(Sink)抽象
castld为了方便各种sink集成,抽象出了 DataSink接口
java
public interface DataSink {
void syncRecords(DataSinkRequest dataSinkRequest) throws Exception;
AppSyncStats getSyncStats();
}我的方案
利用dremio的 create view select as 和 except(取差集)的能力, 针对某些特定的模型,指定调度任务进行数据快照,并进行s3存储(parquet) 快照后的数据可以用来diff也可以用来溯源等. 
反向etl的核心在于扩展性,dremio作为数据湖引擎提供了source端的强大能力,重点在于sink的标准接口声明 对于不同的下游系统,可能存在不同的接口规范,基于pf4j的插件化能力,以及easybatch的writer的标准声明,可以极大程度上提高系统的扩展性.